Conceptualizing a Database: Omeka S
Digitized Occasion Map Papers are made available through an Omeka S installation, an open-source content management system for GLAM institutions, which allows for recording and publishing digitized collections. The system is highly flexible and extensible, capable of integrating existing or custom vocabularies and ontologies. This aspect was very useful for the project, as it allowed for the effective curation of the different forms of data created during the project.
To make this single-point access possible, three forms of data had to be curated: digitized images, digitization metadata, and EAD-encoded finding aids. The project followed the experimental approach of using two different recording practices: bottom-to-top as the documents are digitized, and top-to-bottom for the creation of finding aids. Both have their own logic and data format, making this curation process a complicated task. While both approaches made sense in their internal logic, they produced some conflicts when combined. The bottom-to-top approach took every capturable state of the object as its own entry, while the top-to-bottom finding aid followed the idea of creating logical item units organized hierarchically. For example, a seminar paper by a student as a unit of item consists of texts, maps, scripts, etc., which in turn constitute their own units. A student submitting a seminar paper might only include a map, with the reflective text of the assignment as a marginal note on the map. Here, an answer is required to the question of whether two item units (text and map) or one individual item (a sheet with text and map) should be recorded. What constitutes an individual item and how the items come together to create a higher-level item unit is handled differently in both approaches, creating an automation challenge.
To solve this, an ID system for image files was created, which reflects the materiality of scanned items. For every capture, the material hierarchy used to create the ID is: [stack]*[book/folder/envelope]*[compartment]*[set]*[digitization count]_[recto/verso].
These ID constructions helped to match the groupings in the EAD finding aid, as the information about and sequence of stacks, folders, compartments, etc., were comparable. Thus, the names of the image files could be added to the respective indexing level. Conflicts were resolved manually to ensure proper linking without changing the IDs, preserving both perspectives. This created a secure connection between digitized images, digitization metadata, and EAD-encoded finding aids, as they all reference the same IDs.
To present and make these three constituents accessible, a custom ontology was created, following a model developed in close cooperation with the Harold Garfinkel Archive. One of the primary goals of the experimental digitization of Occasion Map Papers was to offer a reference for indexing and digitization of the entire archive. Through repeated meetings and workshops, a “thing”-based model was created, which defines real-world objects as “things” that are either conceptual or physical. In this approach, “things” do not have hierarchies but relationships, and they are defined by assigned classes and their possible relations to each other. This understanding fits the semantic approach of RDF and related technologies and is representable in Omeka S environment.
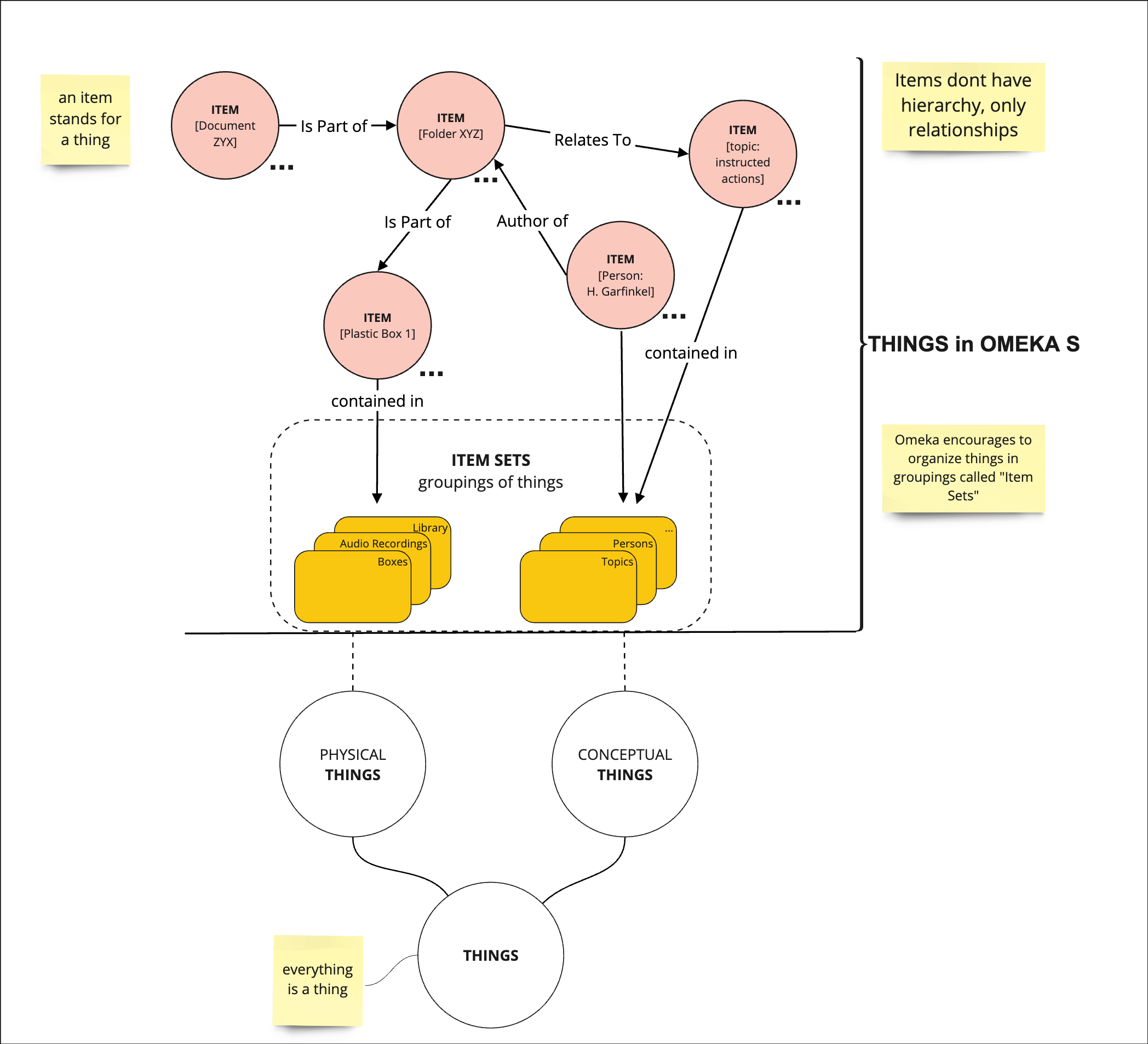
The “Item Set” logic of Omeka S proved useful as well. On the one hand, it allowed easier management and access to “things” sharing similar materiality or in the same class; on the other hand, it could be used as conceptual collections to organize items that belong thematically together, such as Instructed Actions, Studies of Work, Human-Computer Interaction (ELIZA/LYRIC), or occasion maps. These groupings don’t need to be defined in the ontology and can be used freely for the organizational or operational needs of the archive.
Modeling and ontology development are ongoing activities that need to be continually updated and extended. Although the conceptual work included broader class and property definitions, for the Occasion Map Papers, only the parts of the ontology that could be extracted as “things” and “relationships” from the recorded data were considered.
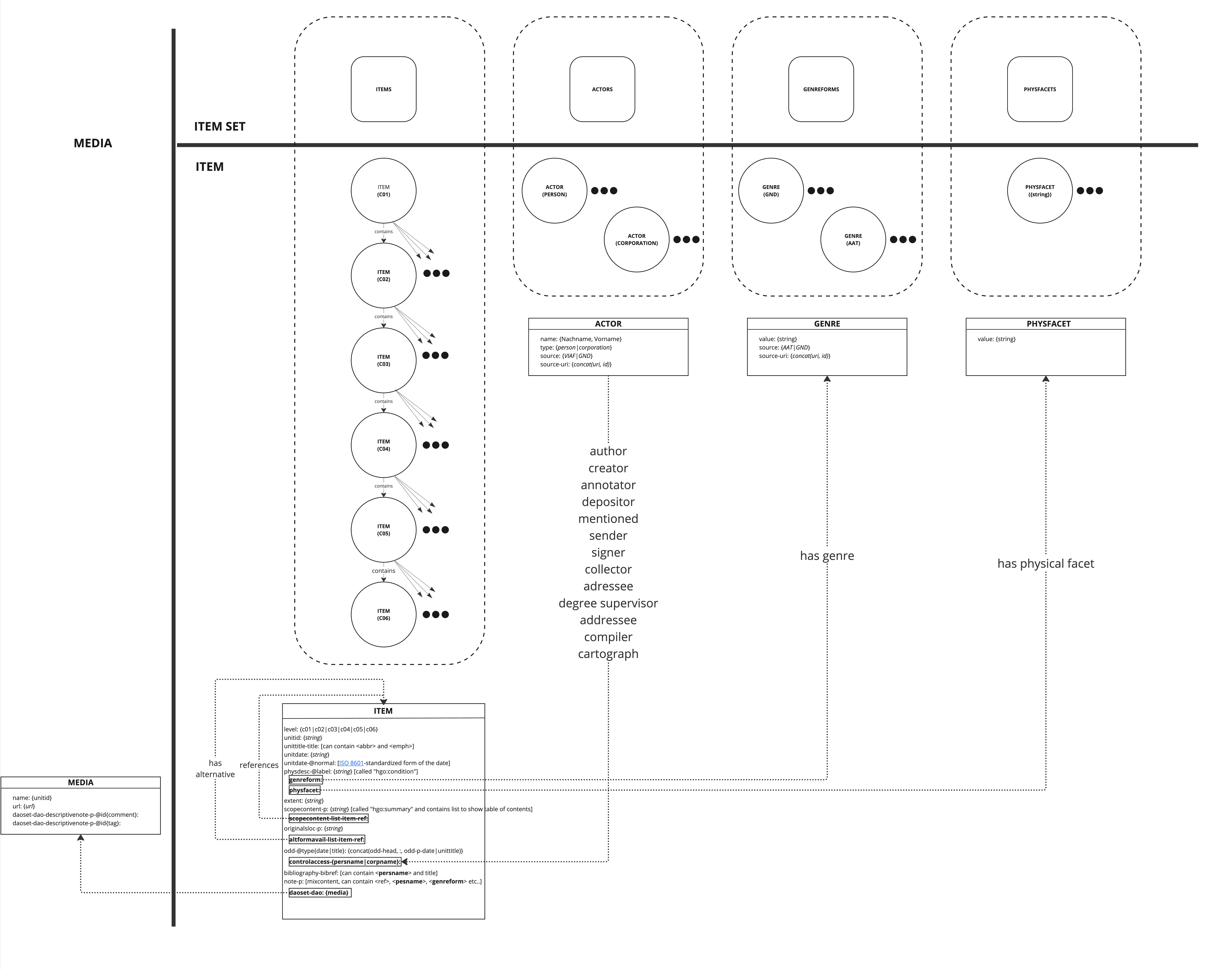
This ontology also represents media files as “things” and utilizes the separate handling of media in Omeka S. Thus, the digitization metadata can directly correspond to media items, while item units can be created as described in the EAD finding aid. As explained in Digitizing Occasion Maps [link to the page], for every state of the same physical item, a row is created with the respective metadata. With this approach, these rows can be assigned to the respective media files, while all these media files are referenced through “Part of Item”-relationship as one and the same archival unit. Additionally, tags from digitization metadata remain functional, allowing users to follow the logic of bottom-up constitution.
Creating separate “things” as items from the document-style format of the EAD finding aid was a challenge not to be underestimated. Complex XSLT pipelines were created to break down the finding aid into its atomic parts without losing the contexts and connections.
For every archival level in the EAD, there are at least four connections to describe relations between archival units: part-of, is-part, has-alternative-form, and related-to. Additionally, persons and organizations act in different roles for these units, such as author, creator, annotator, depositor, collector, cartographer, etc. Units also have genre descriptions with GND and AAT vocabularies attached to them. The XSLT pipelines extract the “things” and their connections, assigning them classes and properties according to the ontology. Through automated import routines, the information units are imported into Omeka S and brought together again through operational IDs.
Unfortunately the results of these efforts can not be shared freely because of the copyright restrictions and personal rights of the persons involved. A research access can be granted. To get a research-access please send a request to the Harold Garfinkel Archive in Boston Newburyport (contact link).